A Practical Guide on How to Reduce Technical Debt
Learn how to reduce technical debt with a practical guide on identifying, prioritizing, and refactoring your code to boost development speed and quality.
A Practical Guide on How to Reduce Technical Debt
Dealing with technical debt isn't just about cleaning up a messy codebase. It’s a strategic process of identifying flawed code, prioritizing fixes based on their real-world business impact, and integrating that repayment work into your regular development sprints. When you approach it this way, a vague, looming problem becomes a clear, manageable workflow. This stops those quick fixes from grinding future innovation to a halt and tanking your user experience.
Tackling Technical Debt Before It Stalls Your Progress
Technical debt is more than just an engineering buzzword; it's the invisible drag on your team's momentum. It's the "interest" you pay later for taking a shortcut today. That interest shows up as slower development cycles, a frustrating number of new bugs, and developers who feel like they’re constantly fighting the code instead of building cool new things.
Before you can even think about fixing it, you need a solid grasp of what is technical debt and the silent toll it takes on your product. Just admitting it exists is the first real step toward getting your team's focus and efficiency back.
This guide is designed to give you a clear path forward. We'll skip the high-level theory and get straight to an actionable framework for making your technical debt visible, measurable, and finally, manageable. The core idea is simple: treat paying down debt with the same seriousness as shipping a new feature.
A Three-Step Framework For Debt Reduction
The journey to a healthier codebase isn't a one-off project. It's a simple, repeatable process that you can break down into manageable chunks. By following a clear structure, you can turn an overwhelming mess into a series of achievable goals that slot right into your existing sprints.
The process below boils it all down to the essentials.
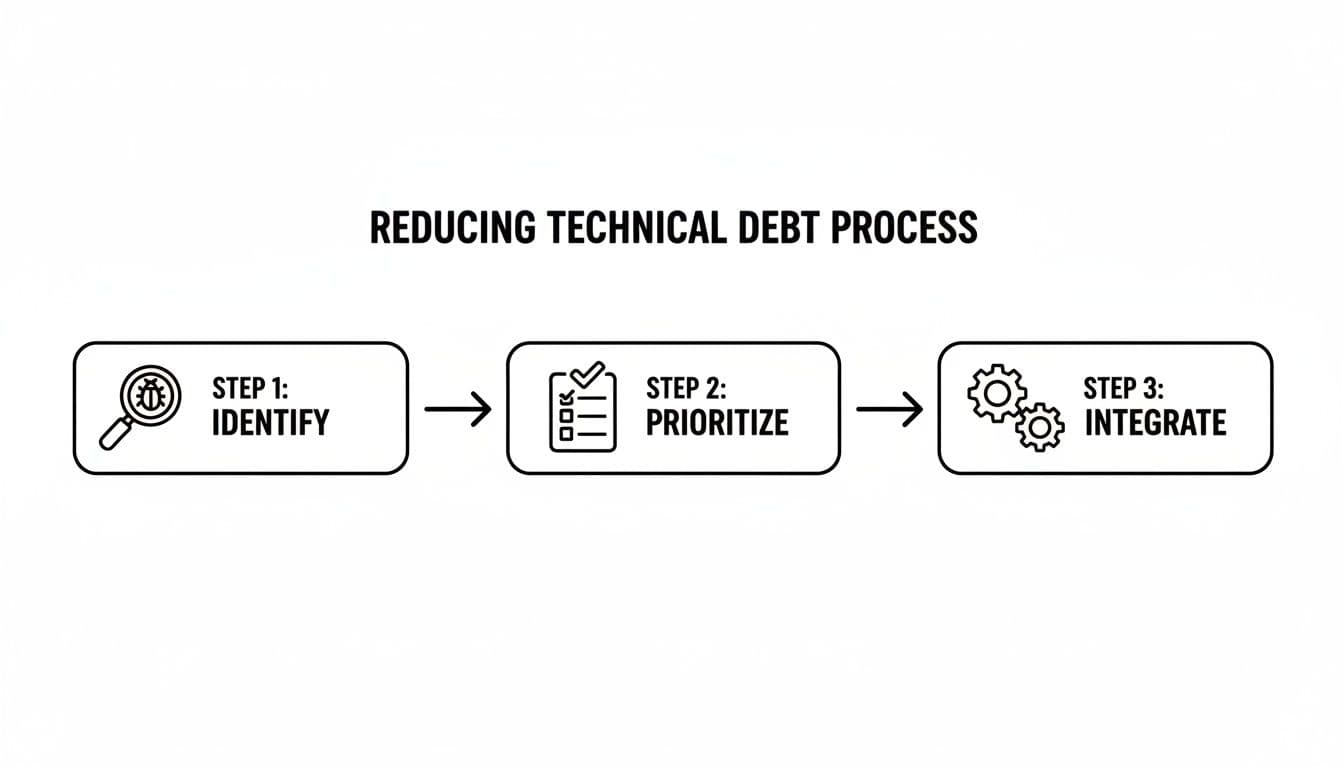
This really is a continuous loop. You have to find the debt, decide what’s most important to fix, and then make that work a part of your team's regular routine.
Your Technical Debt Reduction Roadmap
To put this into practice, here’s a high-level overview of the core strategies we're about to cover. Think of this as your plan of action.
| Strategy | Core Action | Key Benefit |
|---|---|---|
| Identification & Measurement | Use a mix of static analysis, code churn data, and direct team feedback to quantify the debt. | Makes an invisible problem visible and measurable, providing concrete data for decision-making. |
| Prioritization Frameworks | Apply models like the Impact/Effort Matrix to decide which debt items to tackle first. | Ensures you're fixing the problems that deliver the most value to users and developers. |
| Systematic Refactoring | Integrate debt repayment into every sprint using a dedicated time allocation (e.g., 20% rule). | Creates a sustainable habit of continuous improvement instead of relying on massive, risky rewrites. |
| Process Reinforcement | Strengthen code reviews, automate quality gates with CI/CD, and improve QA feedback loops. | Prevents new debt from being introduced, protecting your investment in a healthier codebase. |
This table outlines the journey from acknowledging the problem to building a system that keeps your code clean for the long haul.
From Problem To Action Plan
Let's imagine a real-world scenario. A startup’s frontend team is getting bogged down by slow performance and a never-ending stream of UI bug reports. Every new feature takes twice as long as estimated because small changes cause chaos elsewhere. This is what technical debt feels like in practice. The team is just treading water, constantly fixing old problems instead of building the future of their product.
Turning abstract frustrations into well-defined, prioritized tasks is the key to reclaiming your team's velocity. It's how you go from "our code is a mess" to "this sprint, we will refactor the user authentication module to improve security and reduce login errors by 50%."
The rest of this guide will show you exactly how to make that shift happen. We'll start with the most critical first step: finding and measuring the debt that's hiding in your system. By the end, you'll have a complete roadmap to get your codebase—and your team—back on the right track.
How to Find and Measure Your Technical Debt
You can't fix a problem you can't see. So, the very first step in tackling technical debt is to drag it out of the shadows. We need to move beyond that vague, sinking feeling that "our code is messy" and create a concrete, measurable inventory of the problem areas.
This means digging into your codebase, your processes, and even your team's daily frustrations to find where the debt is hiding. Turning those abstract engineering headaches into real data is the only way to get buy-in from leadership and focus your team’s energy where it’ll actually make a difference. It changes the conversation from complaining about code to building a solid business case for improvement.
Start with Code Analysis and Key Metrics
The most direct way to find debt is to look at the code itself. But staring at thousands of lines of code is a fast track to nowhere. Instead, a combination of automated tools and a few key metrics will help you pinpoint the hotspots causing the most pain.
Start by running a static analysis tool like SonarQube or CodeClimate across your repositories. Think of these tools as an automated, brutally honest code reviewer. They'll automatically flag issues like:
- Code Smells: These are patterns in the code that hint at a deeper problem, like methods that have grown way too long or classes trying to do too many things at once.
- High Cyclomatic Complexity: This is a fancy term for how many different paths exist through a piece of code. A high number means the code is a tangled mess, making it incredibly hard to test, debug, and understand.
- Code Duplication: Finding identical blocks of code copied and pasted across the application is a huge red flag. It’s a maintenance nightmare waiting to happen.
Next, dig into your version control history to analyze code churn. This metric shows you how often a particular file is being changed. If you see your developers constantly touching the same few files just to fix bugs or add small features, that’s a massive signal that the underlying architecture is brittle and riddled with debt.

Connect Code Issues to Business Impact
Technical metrics on their own rarely move the needle with stakeholders. The real magic happens when you translate those findings into dollars and cents. Technical debt isn't just a developer headache; it’s a silent killer of productivity and a drain on company resources.
High-debt organizations often spend 40% more on maintenance and ship features 25-50% slower than their healthier counterparts. That's a huge economic cost. Despite this, a KPMG survey found that a staggering 56% of organizations feel they can't afford to fix these issues, even while dedicating 30% of their IT budgets to dealing with the fallout. By putting a price tag on your debt, you can build a compelling case for taking action.
Pro Tip: Try calculating the "interest payment" on a piece of technical debt. For instance, if a clunky, poorly designed checkout module leads to an extra 10 hours of developer work every month and a 5% spike in related support tickets, you can assign a direct dollar value to that debt.
Tap into Team Feedback and Bug Reports
Don't forget the human element. Your team is on the front lines, and they feel the effects of tech debt every single day. They are one of your best diagnostic tools.
Create a safe space for them to voice their frustrations and document the parts of the system that are a constant nightmare to work with. You'll often find this qualitative data is just as valuable as any automated metric.
Your bug reports are another goldmine. Look for patterns:
- Are most of your bugs clustered in one specific feature or module?
- Do certain kinds of bugs, like performance issues or race conditions, keep popping up?
A high concentration of bug reports in one area is a clear signpost pointing directly to underlying technical debt. This data shows you where your QA efforts are stretched thin and where a focused refactoring effort could bring the most stability. The friction caused by technical debt is also a key factor in developer productivity; for a deeper dive, check out our guide on how to measure developer productivity.
A Practical Example of Debt Identification
Let's make this real. Imagine a QA engineer keeps noticing a recurring performance lag on the user dashboard, especially during peak hours. The user complaints are vague—"it's just slow sometimes."
To turn this into something measurable, the engineer uses a tool like Monito to capture a detailed session replay. The recording includes not just a screen video of the slowdown, but also console logs filled with repeated warnings and network logs showing multiple, redundant API calls for the same exact data.
Suddenly, a generic complaint is transformed into a specific, actionable ticket. Developers can now see that an outdated data-fetching library is the root cause. The debt is no longer an abstract performance problem; it’s a quantifiable issue with a clear source, ready to be prioritized and fixed.
How to Prioritize Technical Debt for Maximum Impact
So you've identified your technical debt. The temptation is to jump right in and start fixing everything. I've seen teams fall into this trap, and it almost always leads to burnout with very little to show for it.
The truth is, not all technical debt is created equal. The real goal isn't to hit some mythical "inbox zero" for your codebase. It's to be strategic and ruthless about what you fix first. You have to focus your team's limited time on the debt that's actively hurting you right now—the stuff that tanks the user experience, grinds development to a halt, or opens up a real security hole. Everything else can probably wait.
Choosing a Framework to Guide Your Decisions
To get past gut feelings, you need a system. A simple but incredibly effective tool for this is the Impact/Effort Matrix, which many teams adapt into a Technical Debt Quadrant. This is all about visualizing where to focus by plotting each debt item based on its business impact versus the effort it’ll take to fix.
Here’s a practical breakdown of how you can categorize your debt this way:
- High Impact, Low Effort (The Quick Wins): Jump on these immediately. They deliver tangible value without blowing up your product roadmap. A classic example is refactoring a confusing API endpoint that new developers constantly stumble over.
- High Impact, High Effort (The Major Projects): These are the big, hairy architectural problems. Think of a core module that needs a total rewrite. You can’t just dive in; these require serious planning, but the payoff in performance or future development speed is massive.
- Low Impact, Low Effort (The Fill-in Tasks): These are the small cleanups you can tackle when you have a bit of downtime. Think updating stale documentation or renaming a few variables for clarity. Nice to have, but not urgent.
- Low Impact, High Effort (The Time Sinks): These are the issues you should actively ignore for now. Spending weeks overhauling a legacy feature that only a handful of customers use is a terrible use of your team’s brainpower.
This exercise transforms a messy, overwhelming backlog into a clear, actionable plan. It's a skill that's very similar to learning how to prioritize product backlog items, and the same principles apply: focus on delivering the most value.
When you're deciding on a system, it helps to see what your options are. Not every framework fits every team, so it’s worth considering a few common ones.
Prioritization Frameworks at a Glance
| Framework | Best For | Key Consideration |
|---|---|---|
| Impact/Effort Matrix | Quick, visual sorting of tasks. Great for sprint planning meetings. | Can be subjective; relies on team consensus for "impact" and "effort." |
| Technical Debt Ratio | Quantifying debt as a percentage of total code to track trends over time. | Requires specialized static analysis tools; doesn't prioritize specific issues. |
| Cost of Delay | Prioritizing work that will deliver the most value the soonest. | Calculating the "cost" can be complex and requires deep business insight. |
| Weighted Shortest Job First (WSJF) | Teams using SAFe that need to balance urgency, value, and effort. | More complex calculation; may be overkill for smaller teams. |
Ultimately, the best framework is the one your team will actually use consistently. Start simple with the Impact/Effort matrix and see if you need more complexity later.
A Real-World Prioritization Scenario
Let's walk through a common situation. A product manager and a lead developer are planning their next sprint. The PM is getting heat about a high cart abandonment rate, while the dev is fed up with how slow and brittle the payment processing module is.
They dig into their bug reports and analytics and surface three key pieces of tech debt:
- Debt A: The checkout button's UI code is a mess, causing it to look weird on certain mobile devices. (Low Effort, Medium Impact)
- Debt B: The payment module has almost no automated tests, so every little change requires a huge, high-risk manual testing effort. (High Effort, High Impact)
- Debt C: An old, unused analytics library is still hanging around in the codebase, slightly bloating the app's initial load time. (Low Effort, Low Impact)
By talking it through, they agree to tackle Debt A right away. It's a quick win that directly addresses the PM's concern about the checkout experience. Debt B is too big for a single sprint, so they break it down, creating a smaller story to just add test coverage to the most critical payment path first. Debt C gets kicked down the road—it’s just not important enough right now.
Make the Debt Visible and Actionable
This is the final, crucial piece of the puzzle: make the work visible. Technical debt shouldn't be some informal, "we'll get to it eventually" side project. It has to be treated with the same respect as a new feature.
That means creating proper tickets in your project management tool, whether it’s Jira, Linear, or something else. Each ticket needs to be well-defined, clearly stating the problem, the fix, and—most importantly—the expected outcome. Think in terms of business value, like "Improve payment API response time by 20%" or "Reduce bug reports related to user profiles by 30%."
When paying down debt becomes a tracked, prioritized, and measurable part of your backlog, it stops being an invisible chore. It becomes what it truly is: a strategic investment in the long-term health and velocity of your product.
Weaving Debt Repayment Into Your Sprints
You've identified your technical debt and even prioritized it. That’s a huge win, but the real work starts now. The most common pitfall I see is treating debt as a "when we have time" activity. That time never comes.
The only way to make real, lasting progress is to weave debt repayment directly into the fabric of your development cycle. It needs to be a non-negotiable part of every single sprint, just like building a new feature.
This simple shift in mindset turns a monumental chore into a manageable, consistent habit. When paying down debt becomes routine, you build a powerful rhythm of continuous improvement that systematically hardens your codebase over time.
Carve Out Dedicated Sprint Capacity
Here’s the single most effective strategy I’ve seen work time and time again: allocate a fixed percentage of every sprint exclusively to tech debt.
Committing 15-25% of each sprint to this work is a game-changer. Why? It forces debt to compete on a level playing field with new features, stopping it from being endlessly kicked down the road. Teams that get this right often find their long-term velocity actually increases, with some seeing 30-50% quicker deployments.
This isn't about every engineer spending one day a week on debt. It's about overall team capacity. You might have one developer dedicate their entire sprint to a complex refactor while the rest of the team pushes features forward. The crucial part is making that commitment during sprint planning and fiercely protecting it from the inevitable pressure to ship "just one more thing."
How to Structure the Work
Once you've walled off the time, how do you actually organize the work? A few models work well, depending on the kind and severity of your debt.
- Hybrid Sprints: This is the go-to for most teams. You simply mix technical debt tickets into your regular sprint backlog alongside user stories and bug fixes. It’s perfect for making continuous, incremental progress.
- Themed Sprints: Got a really messy, concentrated area of debt, like a legacy authentication module? You might dedicate an entire sprint to crushing it. This lets the team go deep without context switching, though it does mean pausing new feature work for a cycle.
- The 'Boy Scout' Rule: This is more of a cultural habit than a formal process. The idea is simple: always leave the code a little cleaner than you found it. If a developer spots a small, related piece of debt while working on a feature—like a poorly named variable or a convoluted function—they fix it right then and there as part of their main task.
A well-defined ticket is your best friend here. "Fix the user profile page" is a terrible ticket. "Refactor the
updateUserProfilefunction to reduce its cyclomatic complexity from 25 to below 10" is a great one. It's specific, measurable, and has a clear goal.
Refactoring with a Safety Net
Actually paying down the debt often means refactoring—a fancy word for improving code without changing its external behavior. It can feel like performing surgery on a living system, which is why having a strong safety net is non-negotiable.
Your best friend here is a comprehensive suite of automated tests. Before you touch a single line of complex code, make sure it has solid test coverage. These tests are your guarantee that your improvements haven't introduced new bugs. This is precisely why understanding what is continuous integration testing is so valuable; it's the bedrock of safe, rapid change.
For those truly intimidating legacy monoliths, an approach like the Strangler Fig Application pattern can be a lifesaver. Instead of a high-risk "big bang" rewrite, you incrementally build new services around the old system. You slowly redirect traffic to the new, modern pieces until the old system is eventually "strangled" and can be retired. It’s a methodical, risk-averse way to modernize while still delivering value every step of the way.
Building a Culture That Prevents Technical Debt
Paying down existing technical debt is crucial, but let's be honest—it's a reactive game. The real win comes from building a system that stops new debt from piling up in the first place. This isn't about a new tool or process; it's a cultural shift where quality becomes everyone's job, not just QA's problem.
When you get this right, your team moves from constantly fighting fires to delivering high-quality work at a sustainable pace. It’s about making the right way the easy way. When your culture and your processes are all pointed toward quality, you spend less time fixing old mistakes and more time building what’s next.
Make Quality a Team Sport
The most effective engineering teams I've worked with treat code quality as a shared responsibility. This goes beyond the developers. It means getting product managers, designers, and even key stakeholders to understand that a healthy codebase is the foundation of a healthy product.
When everyone has skin in the game, the conversation naturally shifts from, "Why isn't this feature done?" to, "What do we need to build this feature right so it doesn't break in six months?"
Here’s how you start fostering that environment:
- Run Blameless Post-Mortems: A critical bug made it to production. The goal isn't to find out who to blame, but why the system allowed it to happen. Was it a gap in testing? Unclear requirements? A rushed review? Focus on fixing the process, not pointing fingers.
- Create a Shared Language: Product managers need to internalize that a "quick hack" today means a much slower, more expensive feature tomorrow. In turn, developers must learn to explain the business impact of technical debt in plain English.
This sense of shared ownership is what makes the change stick. For a deeper dive, check out our guide on how to improve team collaboration and build a more unified engineering culture.
Establish Clear and Enforceable Coding Standards
You can't expect people to write consistent code if you've never defined what "good" actually looks like. Clear, well-documented coding standards are the bedrock of preventing new debt. This isn’t about creating a rigid rulebook; it’s about establishing a shared dialect for your team.
A good set of standards is a living document, not a forgotten file in a wiki. It has to be practical, agreed upon by the team, and easy to find when you need it. The recent trend of 'vibe coding'—where developers ignore standards for the sake of speed—has been linked to a staggering 41% churn rate and a 7.2% drop in delivery stability. In this climate, good governance isn't a luxury; it's a survival tactic.
As experts at Salesforce have pointed out, throwing AI tools on top of messy, inconsistent data just layers new debt on old problems—a crisis they predict will come to a head soon. You can read more about this trend and its impact on pixelmojo.io.
Pro-Tip: Automate your standards wherever you can. Linters and auto-formatters should be built right into your IDE and CI pipeline. This takes the cognitive load off your developers, turning standards from a manual chore into an automated guardrail.
Strengthen Your Code Review Process
If I had to pick one thing, a rigorous code review process is your single most powerful tool for catching technical debt before it merges. It’s more than just a bug hunt; it’s a critical moment for knowledge sharing, mentoring junior developers, and upholding your team's quality bar.
A great code review is a thoughtful dialogue, not just a quick "LGTM."
To make your reviews more effective:
- Keep Pull Requests Small. It’s nearly impossible to give meaningful feedback on a 2,000-line PR. Small, focused changes are easier to understand, review thoroughly, and merge without causing chaos.
- Focus on the "Why." Don't just point out what’s wrong. Explain why a different approach is better, tying it back to your coding standards or architectural principles.
- Use a Checklist. A simple PR template with a checklist can be a lifesaver. It reminds reviewers to check for common oversights like missing tests, unclear documentation, or potential performance bottlenecks.
Automate Quality Gates in Your Pipeline
At the end of the day, humans make mistakes. That’s where automation becomes your safety net. Your CI/CD pipeline is the last line of defense against new technical debt being introduced into your codebase.
By setting up automated quality gates, you create a system that physically stops bad code from being merged. These gates can automatically run your test suite, check that code coverage meets a certain threshold, and scan for security vulnerabilities. If any of these checks fail, the build is blocked.
This isn't about punishing anyone; it's about creating a powerful, immediate feedback loop. It reinforces your quality standards on every single commit, ensuring your codebase gets healthier over time, not messier.
Frequently Asked Questions About Technical Debt
Working through technical debt can feel like you're navigating a maze. Even with a solid plan, you're bound to run into specific challenges and tricky questions along the way. Let's tackle some of the most common ones that come up when teams finally decide to get serious about cleaning up their codebase.
How Do I Convince My Manager to Prioritize Technical Debt?
The trick is to stop talking like an engineer and start talking like a business owner. Forget abstract terms like "code quality" or "refactoring." Instead, you need to connect the dots between the technical problems you see and the business metrics your manager lives and breathes every day.
Bring them data, not just complaints. For instance, instead of saying the code is a mess, try this: "The complexity in our payment module added 20% more development time for new checkout features this quarter. We also saw a 15% spike in customer support tickets related to payment errors." Suddenly, you've framed the issue in terms of slower delivery and rising operational costs—two things that definitely get a manager's attention.
A great way to get started is with a small, low-risk pilot project. Propose dedicating 20% of a single sprint to fixing one high-impact piece of debt. Before you start, forecast the improvements you expect to see in development speed or system stability. Afterward, make sure you measure and report back on the actual results. This proves you can deliver a tangible return on investment and builds the trust you need for a bigger commitment.
What Is the Difference Between Good and Bad Technical Debt?
The real difference between "good" and "bad" technical debt all boils down to intent. Not all shortcuts are created equal; some are calculated risks, while others are just sloppy mistakes.
- Good Technical Debt: This is the debt you take on knowingly. It's a strategic decision made to hit a crucial business goal, like launching on time or quickly validating a new feature with real users. The team is fully aware of the tradeoff and has a concrete plan to address the shortcut later. Think of it as a loan taken out for a specific, valuable purpose.
- Bad Technical Debt: This is the unintentional kind that just happens. It sneaks into the codebase from rushed work, knowledge gaps, inconsistent practices, or simply a lack of awareness. This type offers no strategic benefit—it only creates friction, making every future change slower and more painful.
The goal is never to have zero technical debt; that's just not realistic. The real aim is to manage it like a portfolio, making smart, deliberate tradeoffs while actively stamping out the unintentional, costly debt that silently drags your product down.
What Are Some Recommended Tools for Managing Technical Debt?
There’s no single magic tool, but you can build a powerful toolchain that supports you at every stage, from discovery to prevention. The best approach is to pick tools that fit into the different parts of your workflow.
For Identification and Analysis
Static analysis tools are your first line of defense. They act like an automated, always-on code reviewer, scanning your codebase for code smells, overly complex methods, and security holes.
- SonarQube: A comprehensive, open-source platform for continuously inspecting code quality.
- CodeClimate: Provides automated code review that flags everything from duplication to maintainability issues.
For Tracking and Prioritization
You don't need a separate system for this—your existing project management tool is perfect. The key is to treat technical debt tickets with the same respect as feature work by creating detailed, estimated, and prioritized tickets.
- Jira: The go-to choice for many teams to create and manage debt-related tasks right in the backlog.
- Linear: A faster, more modern alternative that’s become popular with developer-focused teams.
For Diagnostics and Bug Reporting
Often, the hardest part is connecting a vague bug report from a user to the underlying code causing the problem. Tools that capture the full context of what was happening when an issue occurred are absolute lifesavers.
- Monito: Automatically captures screen recordings of user sessions along with console logs and network requests. It turns a fuzzy "it's broken" ticket into a developer-ready report that shows you exactly what went wrong.
For Prevention
The best way to manage debt is to stop creating it. By integrating quality gates directly into your CI/CD pipeline, you can automatically enforce your standards and ensure new code is clean before it gets merged.
- Jenkins: A highly configurable automation server for building, testing, and deploying your code.
- GitHub Actions: Lets you build powerful, automated workflows directly inside your GitHub repository.
By picking the right tools from each of these categories, you can build a system that not only helps you pay down existing debt but also prevents it from piling up again.
Monito helps you connect the dots between user-reported bugs and the technical debt causing them. By automatically capturing the complete context—including screen recordings, console logs, and network activity—it transforms vague complaints into clear, actionable engineering tickets. Stop wasting hours on back-and-forth and start fixing issues with confidence. Start your free trial today at Monito.